Company
Apr 14, 2026
Why We Built Seltz

Antonio Mallia
We're releasing our web search API to the public, starting with US news. Here's why we built every component ourselves, and what owned infrastructure unlocks for engineers building on top of it.

I'm proud to announce the public release of Seltz. A web search API built for agents that need real-time information at low latency.
Our team spent months building every part of our product from scratch. It was painstaking, and took longer than expected. But the result is clear: our infrastructure gives engineers a genuinely independent source of web knowledge for their agents, starting with real-time news.
I want to explain why this is so important to us, and what it unlocks for you.
My first published research paper made the query processing algorithms behind large-scale search engines twice as fast. That's how I got into search, and ultimately to Amazon.
At Amazon we built the web search engine that powers Alexa's question answering. The system searched the open web, retrieved full pages, and generated spoken answers from what it found. The key difference from conventional search was who was reading the results. Alexa was not displaying ten blue links for a human to scan. It was consuming retrieved text and producing a response. We built search for the non-human consumer years before the term "RAG" existed.
At Pinecone, I saw the same gap from the other side. I was inside one of the most widely used vector infrastructure companies, working closely with dozens of AI-native teams building real products. What they needed, repeatedly, was web knowledge. A vector database stores and retrieves what you give it, but it cannot go find what exists on the internet. Pinecone built an agentic workflow called Pinecone Assistant, and after spending time with it, I realized it would be fundamentally smarter with access to the open web.
I kept seeing the same problem everywhere I went. Not the vector database companies, not the agent framework companies, not the model providers — nobody was building the infrastructure agents need to access real-time web knowledge. That realization is what led to recruiting a team of retrieval experts to build Seltz.
We did not fork an open source project and configure it. We implemented from first principles because we are the people who work on those principles.
Why we built Seltz from scratch
The most important part of our product is that every part of our infrastructure is built from scratch.
Why? There are open source search engines, commercial crawlers, and a dozen search API providers already in the market. The answer comes down to two things: existing infrastructure cannot be fast, cost-effective, and capable of indexing the web at the same time, and agents need a diversity of information that only a truly independent data pipeline can provide.
There is no production-ready open source solution for web search at the scale the internet demands. The available tools are designed for enterprise search or small-scale applications: thousands or millions of documents in a controlled index.
Web search operates on hundreds of billions of documents across a constantly changing surface. The result of trying to stretch these tools to web scale is either prohibitively expensive, too slow, or unable to handle the document volumes. Building from scratch allowed us to push these constraints to their limits.
The more important reason is what wrapping someone else's infrastructure (ranking system or data) actually means for agents. Most search API providers today do not operate their own index. They route queries to Google, Bing, or another large-scale engine, then repackage the results.
When your agent already has access to Google directly, and your search API provider sources its results from Google's index, you are paying for a second call that returns largely the same documents. Reranking the same documents does not add new information.
Foundational labs building LLM-powered products told us this directly. They integrated a search API alongside their existing search infrastructure, and the document overlap was high enough that the additional provider did not justify its cost. They didn’t need access to the same results large-scale engines provide. They needed different documents, in a different format — full pages, not snippets — with ranking driven by relevance to the agent's task, not by human click patterns.
So we built our own crawler, our own models, our own retrieval stack. When you query Seltz, the documents come from an index we built and maintain. If you run Seltz alongside Google or Bing or Brave, you get genuinely different results: different documents, different rankings, different context for your agent to reason over.
Your agent isn't getting a second opinion from the same source, it's getting an independent one. And agents that reason over independent sources produce better answers.
What independent infrastructure gets you
The payoff is three properties that only exist because we own the entire stack: 7x lower latency that competitors, dynamic configurability, and diversity of results that we mentioned earlier. Together, they change the economics of how you can build agents that depend on web knowledge.
And the best part? None of this comes at the cost of retrieval quality. Our evaluation framework measures this rigorously, here are the results as of April 11th.
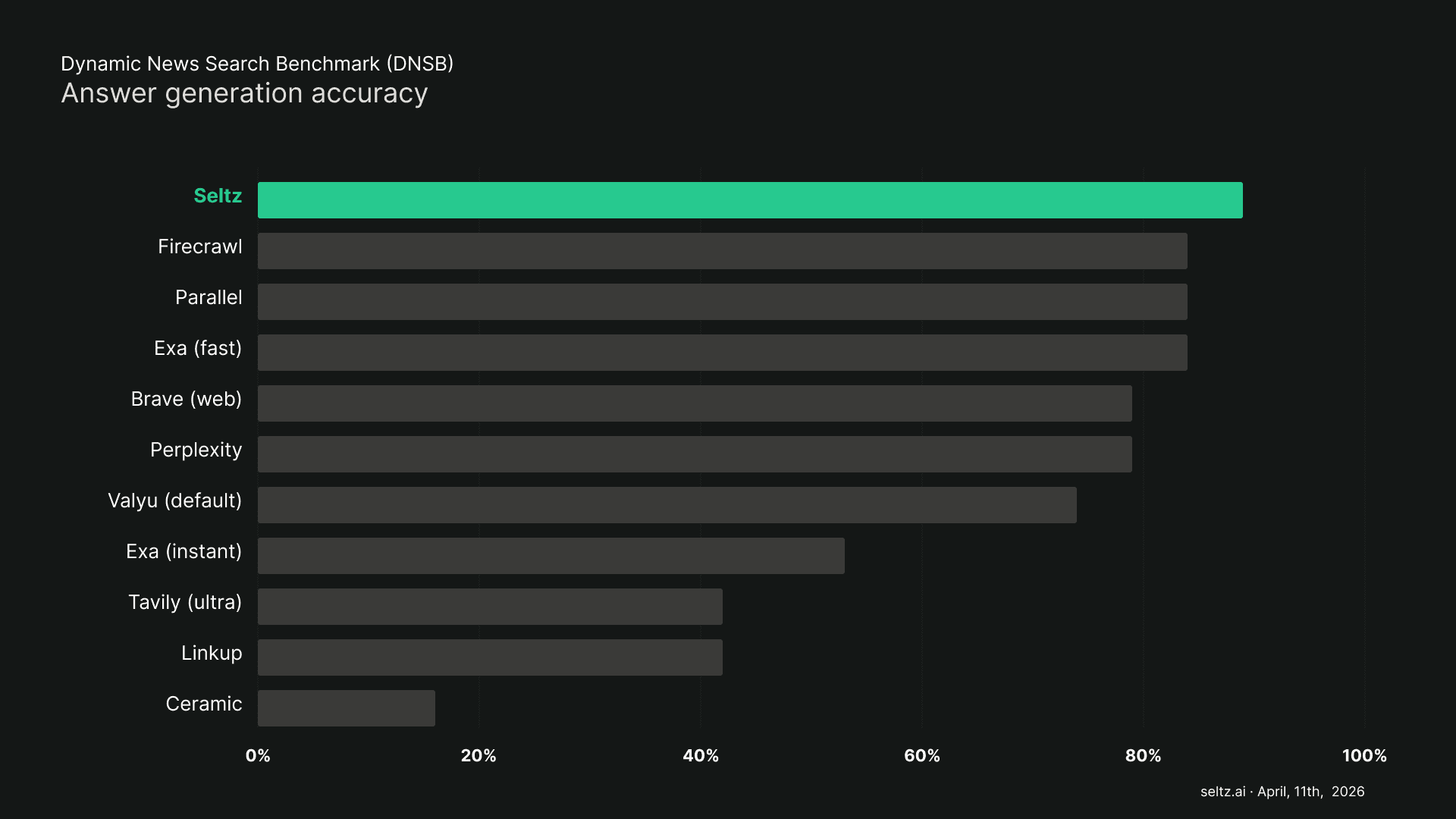
To make this concrete, consider an agent built to monitor the ongoing war in Iran. The conflict is in its second month, with developments breaking across military operations, diplomatic negotiations, oil market disruptions, and humanitarian impacts simultaneously. Dozens of new articles published every hour. This is exactly the kind of information environment where the differences between providers become visible.
Lower Latency
We benchmark against every major search API provider. The average response time across providers was approximately 1.2 seconds per query, ranging from 120 milliseconds to six seconds.
Seltz consistently responds in under 250 milliseconds, 7x-30x faster than other providers. This number impacts infrastructure and user experience. In most agent architectures, the model cannot produce its first token until the search results come back.
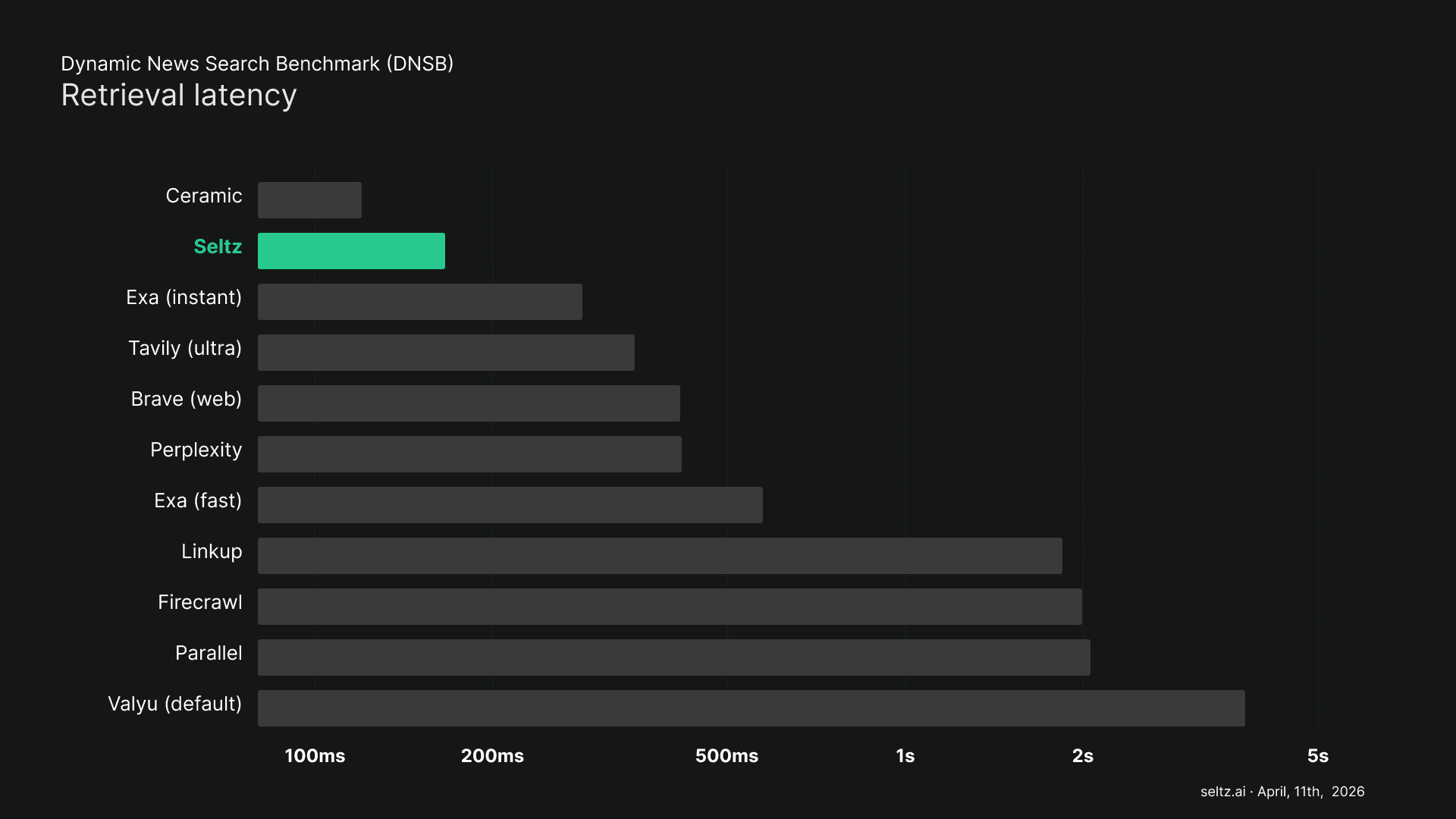
A 1.2 second search means 12. seconds before the user sees anything. At that speed, the Iran war monitoring agent has to build its query without knowing the current state of the conflict. It gets one shot: a single broad search string that tries to capture a multi-front situation.
At under 250 milliseconds, the agent can search first for the latest developments, read the results, then form follow-up queries based on what it actually finds. It can discover that Strait of Hormuz shipping is the lead story, search specifically for economic impacts, then search again for the diplomatic response.
Each query builds on the last, and the user isn't waiting forever to get the information they need.
New Degrees of Freedom
For the Iran war monitoring agent, the system it queries was purpose-built for this kind of request.
Our news vertical is not a filtered slice of a generic web crawl. It is a dedicated index where every document was ingested through a pipeline designed for news: optimized for freshness, cleaned for the kind of structured content that LLMs consume well, and ranked by a retrieval model built for this domain.
That level of specificity is only possible because we own every component in the pipeline. When we want to change how documents are ranked, we change our ranking algorithm. When we want to expand into a new data vertical, we point our crawler at new sources and configure the pipeline.
Adding a vertical is an engineering decision, not a dependency negotiation.
Diversity of results
If the Iran war monitoring agent sends a query about Strait of Hormuz disruptions to Google and to a provider that wraps Google's index, the two result sets will overlap heavily: the same wire service reporting, the same major outlet coverage, the same sources repeated under different headlines; all ranked for human clicks, not agent consumption.
If the agent sends that same query to Seltz alongside Google, it gets documents from a completely independent index. For a conflict with this many dimensions, where Al Jazeera's reporting on Iranian diplomacy tells a different story than CNN's coverage of US military operations, and where regional outlets in the Gulf states are covering economic impacts that Western media underreports, that diversity is the difference between an answer that summarizes one narrative and an answer that synthesizes across multiple independent perspectives.
These three properties compound. Low latency lets the agent decompose a fast-moving story into precise sub-queries. Configurability means the index is tuned for breaking news. Diversity means each query returns documents the agent would not get from its other providers.
Why the team matters as much as the architecture
Building a state of the art search engine from scratch requires a team that understands the underlying science, not just the engineering. And we have one.
Information retrieval is a small field. I started studying at the University of Pisa, before ultimately getting my PhD, with a focus on large-scale web search engines, at NYU. Pisa is a small city with an unusually high concentration of people interested and knowledgeable about search.
That community traces back to a single student who, almost 30 years ago, discovered the source code of an early search engine and built a research group around it. That person is now a director at Google and one of our angel investors.
The team we have built carries that research lineage directly into the product. Most of us come from academic research backgrounds, and the ones who don’t have learned it over years of engineering excellence. We are reviewers at top-tier IR conferences. We publish papers and implement the findings in production.
A concrete example: the standard model for lexical retrieval is BM25, an algorithm from 1994 that nearly every search system uses today. At Seltz, we do not use BM25. We built a next-generation model from research I published years ago, rebuilt from the ground up to significantly outperform BM25 on the metrics that matter for our use case. That model powers our production system today.
What we’re releasing today started as research we published, problems we studied, and products we built that touch millions of people. We're eager to see how others in the space build on our work.
Where we are and where we are going
What we are releasing today is a knowledge provider for AI agents. We built it from scratch, and started with US news because it forced us to build infrastructure we can use across every new vertical.
Seltz is best for queries where freshness, latency, document diversity, and agent-optimized retrieval matter. Our index makes every source in your stack more valuable by adding context they don’t provide. We are not replacing or building on top of existing search. We are redesigning it from the perspective of context engineering for AI.
There are things on our roadmap we have not yet shipped, from on-prem deployment to new retrieval paradigms. These will be possible only because we made the decision today to build the product from scratch. It is an investment for the future.
We built every component from scratch because it was the only way to achieve the properties agents actually need. We staffed the team with researchers because this problem requires more than engineering. And we are releasing it today because it is ready to be tested by the engineers building the next generation of AI-powered products.
If you’re building agents that need real-time web knowledge, Seltz is ready.
Related Articles