Company
Apr 21, 2026
Why We Built for News First

Max V
LLMs have a knowledge cutoff. Agents need current information. We built Seltz to close that gap — and started with news because it was the hardest problem we could have chosen.

Models don’t know what happened today
We built Seltz because the infrastructure agents use to find information was designed for a different consumer entirely.
We recently released an API that allows agents to retrieve news stories that break within the hour. We are not building a news search company. News was the right first problem because it was not the easiest one.
Large language models know a great deal. They have absorbed more text than any person will read in a lifetime, and they can reason across it with real precision. What they cannot do is know what happened recently.
Training a model is expensive — no organization runs a full training cycle every hour, or even every month. The knowledge baked into a model has a cutoff, and that cutoff is always in the past.
We built Seltz to close that gap. For engineers building agents, that means three things in practice:
Results that are up-to-date within the hour
A cost structure you can build a product on top of
No arbitrary limits on what you can retrieve
These properties are connected: we could not offer all three without owning the infrastructure end to end. The rest of this post is about the engineering behind that decision, and why news was the right place to prove it.
Why news is the hardest freshness problem
Not all information ages at the same rate.
A textbook on thermodynamics is as useful today as it was five years ago. A product changelog from last quarter is stale but not useless. A news story about a central bank decision, a festival lineup change, a geopolitical development, or a sold-out show that just added tickets can be outdated within the hour it was published.

For agents operating on time-sensitive tasks, this isn't an edge case. A trading algorithm that retrieves news about a company's earnings from two hours ago may be acting on information the market has already priced in. A compliance monitoring agent working from yesterday's regulatory filings is not monitoring compliance. A news aggregation product that surfaces stories from this morning when the story broke this afternoon has failed at its core job.
The freshness requirement for news isn't "recent."
It is specific: a story published on a news outlet should be searchable within approximately one hour of publication. That is the SLA we set for the US News API. It reflects the actual latency tolerance of the agent workflows that depend on this kind of data.
That SLA is harder to meet than it sounds. Most knowledge providers do not publish freshness SLAs at all. Those that do measure freshness in hours or days, not in the sub-hour window that time-sensitive workflows require. That gap exists because meeting a sub-hour freshness guarantee at web scale requires solving an infrastructure problem most systems were not designed to solve.
Why batch indexing fails for news, and what works instead
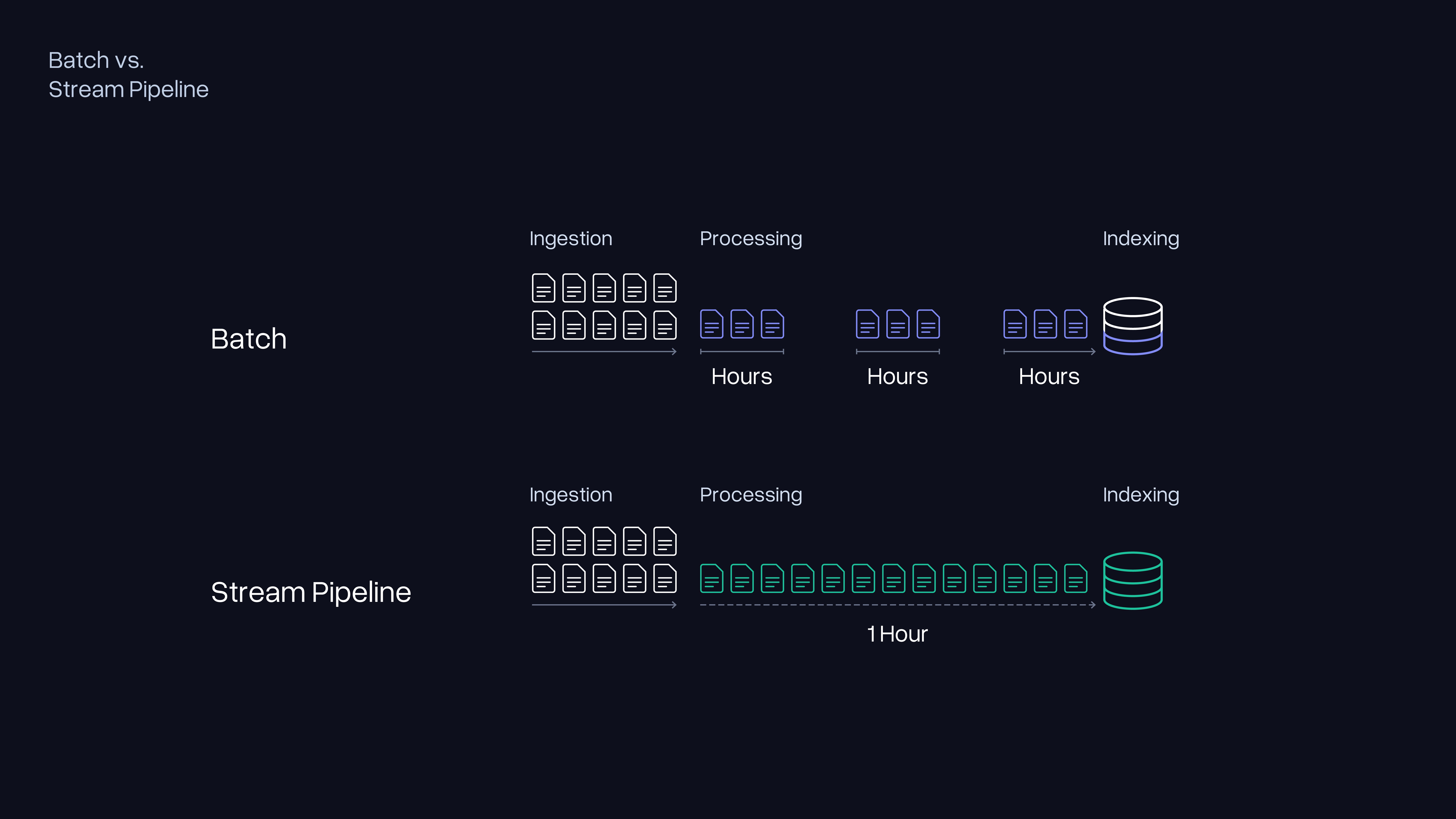
Building a search index follows a predictable pattern. You crawl documents, process them, and write them into an index. When the source data changes, you update the index. For most content, that update cycle can run on a schedule — hourly, daily, or even weekly, depending on how quickly the underlying data changes. For news, that update schedule breaks down immediately.
The naive approach is to rebuild the index frequently. Run the full indexing pipeline every few minutes, and the index stays current. The problem is cost. A full index rebuild at web scale is not a lightweight operation. It requires replacing the live index without disrupting active queries. At the scale required for a production news API serving millions of queries, running that cycle every five minutes would consume compute resources at a rate that makes the economics of the product unworkable.
Incremental indexing offers a partial answer. Rather than rebuilding everything, you identify what has changed and update only those documents. This works well when changes are infrequent and bounded. News produces hundreds of articles per hour across thousands of sources. The incremental update is effectively continuous, which brings you back to the same infrastructure requirements as a stream-oriented system, but with the added complexity of tracking deltas on top of a batch-oriented foundation.
We had substantive internal conversations about this. The batch-oriented path had real advantages: the tooling support is better, operational behavior is more predictable, and the initial engineering investment is lower. The stream-oriented path meant building more from scratch. Hunter and Roberto worked through the options carefully before we committed. The conclusion was that batch architecture imposes a freshness floor you cannot break through without rebuilding. If the product requirement is sub-hour freshness at web scale, batch is not a slower version of the right answer. It is the wrong architecture.
Stream-oriented architecture solves this by eliminating the batch cycle entirely. Rather than accumulating documents and processing them together on a schedule, every document that enters the system flows continuously through each pipeline stage. Ingestion feeds directly into processing. Processing feeds directly into indexing. No accumulation point exists where documents wait for the next cycle to begin.
The practical consequence is that a news article published on an outlet's website moves through our pipeline and becomes searchable within approximately one hour of publication. That latency comes from a pipeline with no batch cycles, not from a faster version of one.
At web scale, with the specific requirements of a news knowledge provider, available open source tooling introduced constraints that would have become architectural debt within months. We made the decision to build the core components internally rather than adapt tools that were not designed for this problem. That decision costs more up front and means the infrastructure fits the constraint rather than working around it.
Why standard benchmarks don't measure freshness
The information retrieval research community has built rigorous tools for evaluating how well a system retrieves relevant documents. Benchmark datasets provide a corpus, a set of queries, and relevance judgments. A retrieval system is scored on how well its results match those judgments. This is genuinely useful work. It has driven meaningful progress in retrieval quality across a wide range of domains.
It cannot measure freshness at sub-hour latency, and the reason is structural rather than a gap that better benchmark design would close.
Producing a benchmark dataset takes time. Researchers identify a domain, collect a corpus, generate queries, and annotate relevance judgments. That process takes weeks at minimum. By the time the dataset is published and available for evaluation, the corpus it contains is weeks or months old. For domains where content changes slowly, that lag is irrelevant. For news, it means the benchmark is evaluating retrieval quality on content that is no longer news by any practical definition.
As of early 2026, most publicly available benchmarks that include news retrieval tasks are working with corpora that are at least one to two months old. A system that scores well on those benchmarks has demonstrated that it can retrieve relevant documents from a static corpus. It has not demonstrated that it can surface a story that broke forty-five minutes ago.
There is a second problem. Because benchmarks are known quantities, systems can be optimized specifically to perform well on them. It’s possible to maintain dedicated indexes tuned for benchmark query patterns. Performance on those benchmarks look strong, but performance on queries outside the benchmark distribution look different.
Benchmark overfitting is a documented problem in machine learning broadly. It is particularly acute for news retrieval, where the benchmark corpus and the live retrieval problem are measuring structurally different things.
We evaluate Seltz differently. The question we ask is not whether our results score well against a static relevance judgment. The question is whether an agent retrieving from Seltz succeeds at its task better than it would with alternative retrieval. That is a harder measurement problem, and we do not claim to have solved it completely. What we can say is that optimizing for benchmark scores on static corpora would not get us closer to the answer.
More about the US News API
The US News API is Seltz's first publicly available vertical.
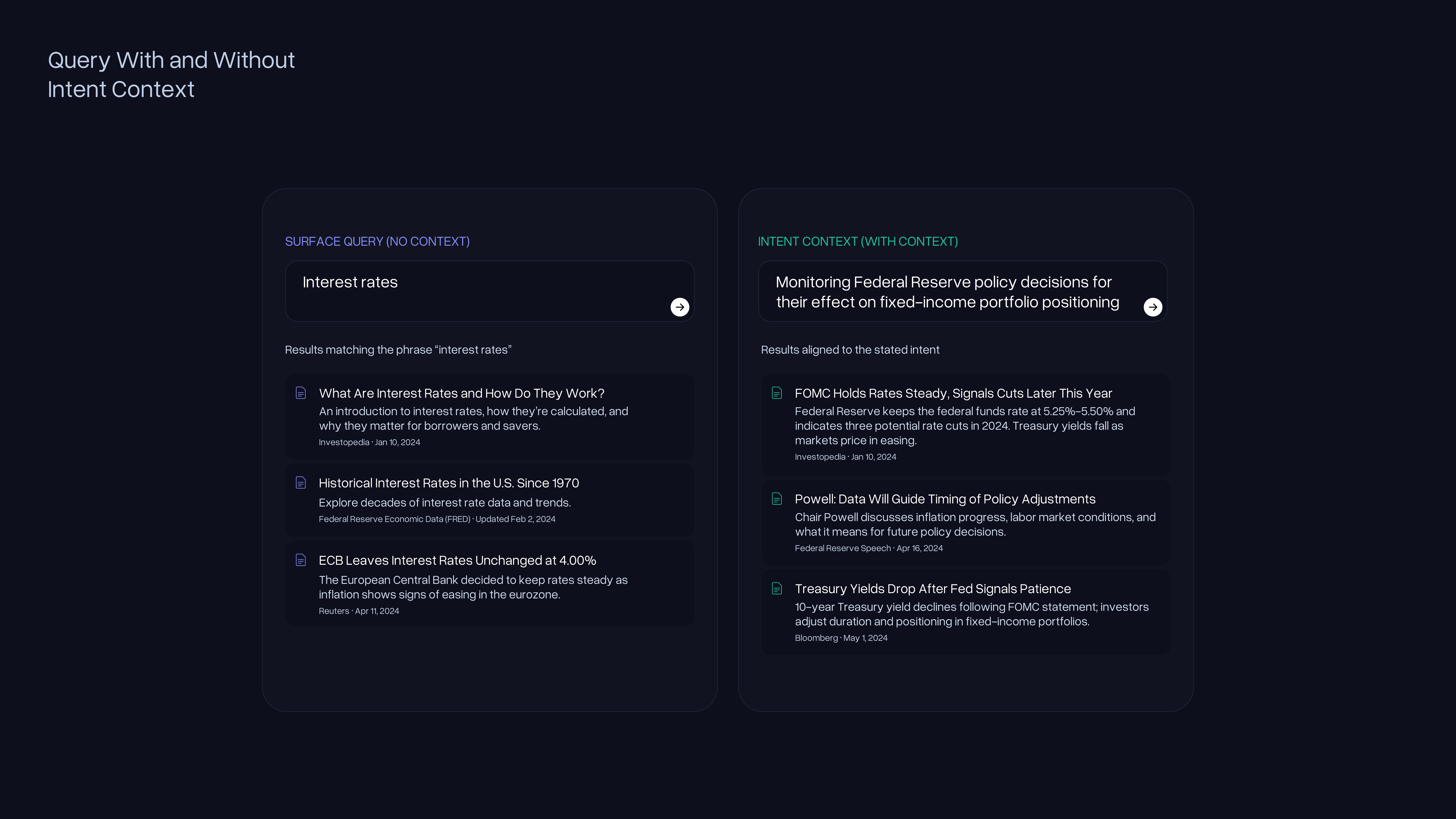
Our API indexes US news articles and returns knowledge for agents to consume as context. The freshness SLA is approximately one hour from publication to searchable. A developer submits a query along with an optional context field that describes what the agent is actually trying to accomplish.
Your trading algorithm can communicate that it is monitoring news about a specific company for market-moving developments. Your compliance tool can specify the regulatory domain it is tracking. The result set reflects that intent, not just the surface keywords in the query string. Agents can provide paragraphs of intent context, and the API is built to use it.
We are not trying to replace Google or Bing. The right mental model is complementary: an agent's routing logic should be able to choose — call a general web search API for broad coverage, call Seltz when it needs fresh, vertical knowledge, from an owned index.
These are different tools for different queries, not competing ones. The tradeoff with providers who source results from Google's index is document differentiation: if you are already calling Google's API, adding a provider that draws from the same index returns overlapping documents.
We own our index. The documents we return are genuinely different, ranked by our own retrieval logic, with freshness managed at the ingestion level. For the queries where that difference matters — breaking news, time-sensitive agent tasks, information that changes within the hour — owned infrastructure is what makes the SLA possible.
News is available now. More is coming.
Related Articles